SpringWeb 线程泄漏问题排查
现在是什么问题?
最近开发环境有个服务只要是超过 2 天没有重启/构建上线的话, 都会出现请求超时的问题.弄的前端和嵌入式开发的同事老是找我麻烦 😅
周末刚好有空去加班, 办公室也比较安静, 比较有耐心来排查这个问题了.
开发环境虽然是个直接 java -jar 部署的, 因为有用 mircometer 来暴露一些监控数据, 我也是把它接入了监控了, 在 Grafana 就能看到 JVM 情况
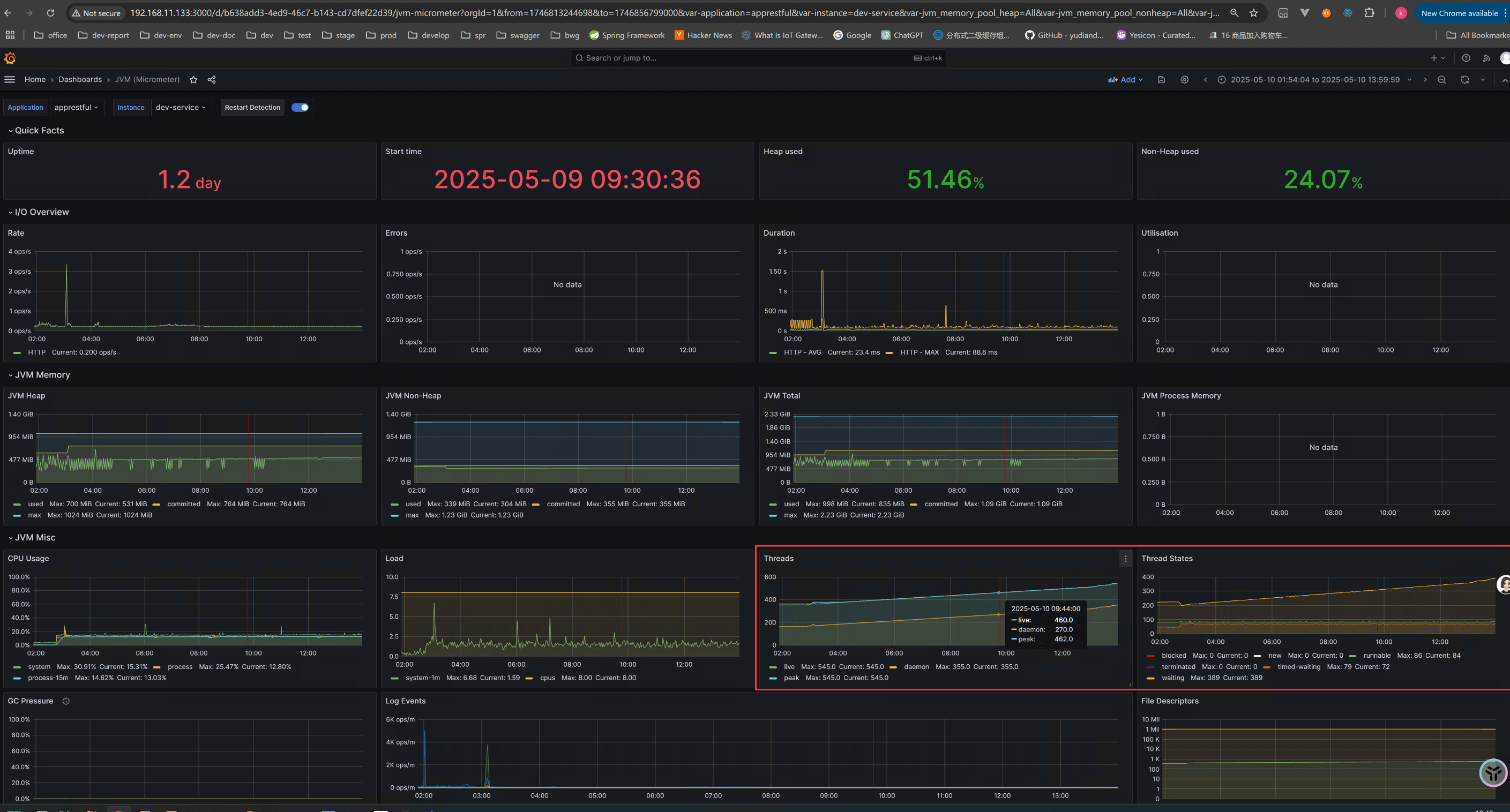
可以看到 Thread 和 Waithing 状态的 Thread 不断增加, 怎么了, 看起来是线程泄漏了? 我们的代码虽然管理是不规范, 到处都有地方开线程池, 但是之前还是用的好好的呀「手动狗头」
没事没事, 知道有异常出现了, 都好办, 直接上去机器上 dump 一些 log 出来看看就好, 我们这不还在「犯罪现场」呢嘛
看看怎么个事儿
开发环境都是丢在一台虚拟机上的, 而且就是直接 java -jar 部署的
天然的让我好把日志导出来, 我直接一个 jps -lvm 查看那个问题服务的 PID
然后再来一个 jstack:
通过 jstack pid > thread_dump.log 把线程和上下文都 dump 出来
然后再来请上我们的 Linux 三剑客之二: awk, grep
这里你以为我的 Linux 命令用的很溜嘛? 其实都是 ChatGPT 给我的, 没了他我可就是个菜鸡 😭
执行:
awk '/^"/ {thread=$0} /java.lang.Thread.State: WAITING/ {print thread}' thread_dump.log | awk -F'"' '{print $2}' | tee /dev/tty | wc -l输出:
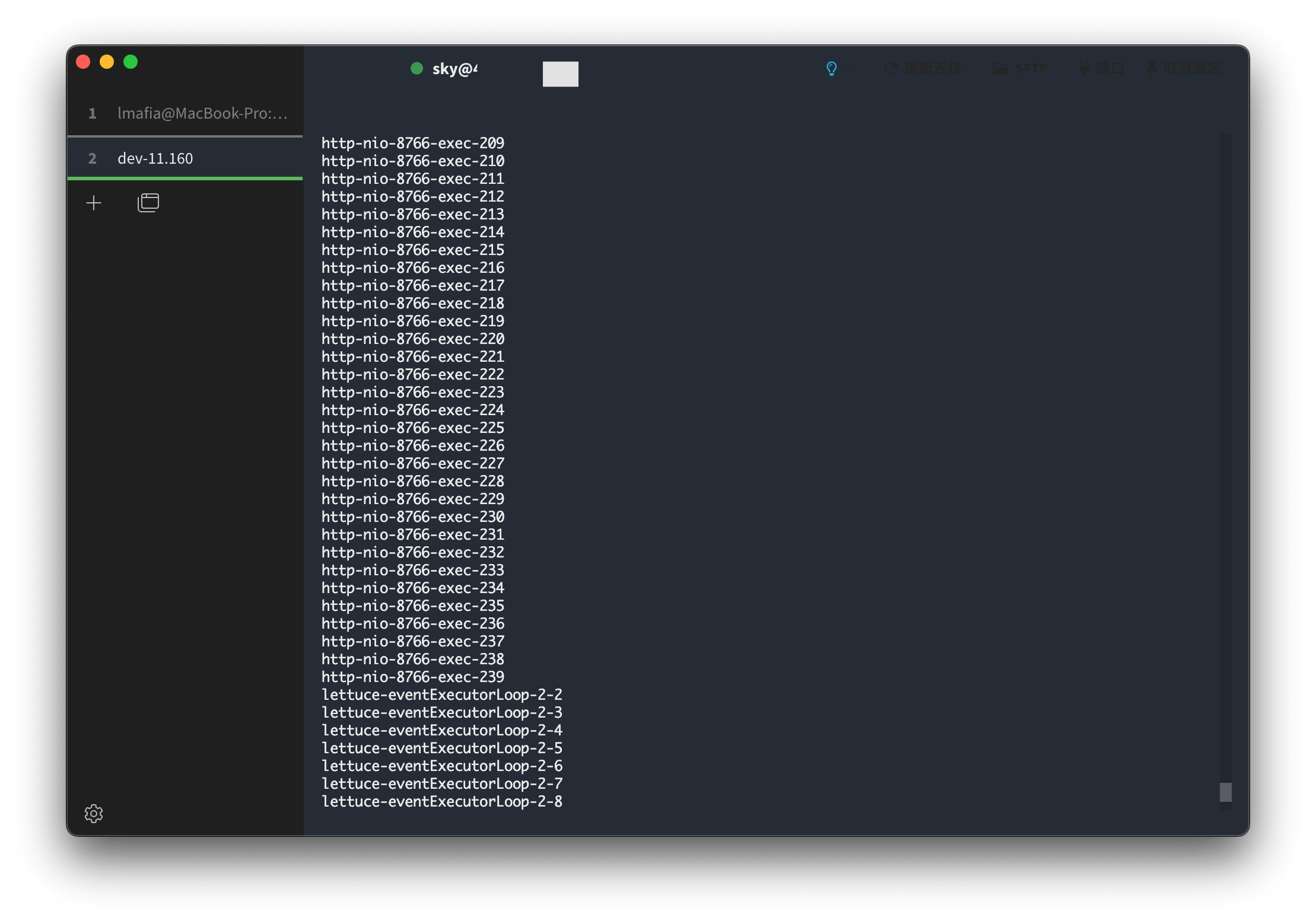
好家伙, 大部分都是 http-nio-exec-* 证明都是请求没有释放还是咋地啊?
咱们可是都是 Spring Boot 工程师呢 , 用得当然是我们的 SpringBoot + SpringWeb (Tomcat 内置)
我们最近也没升级啥 Tomcat 的版本, 也没修改什么配置的, 到底咋个回事?
挑几个请求的线程看看日志吧, 发现基本都处在 WAITING(Park)状态
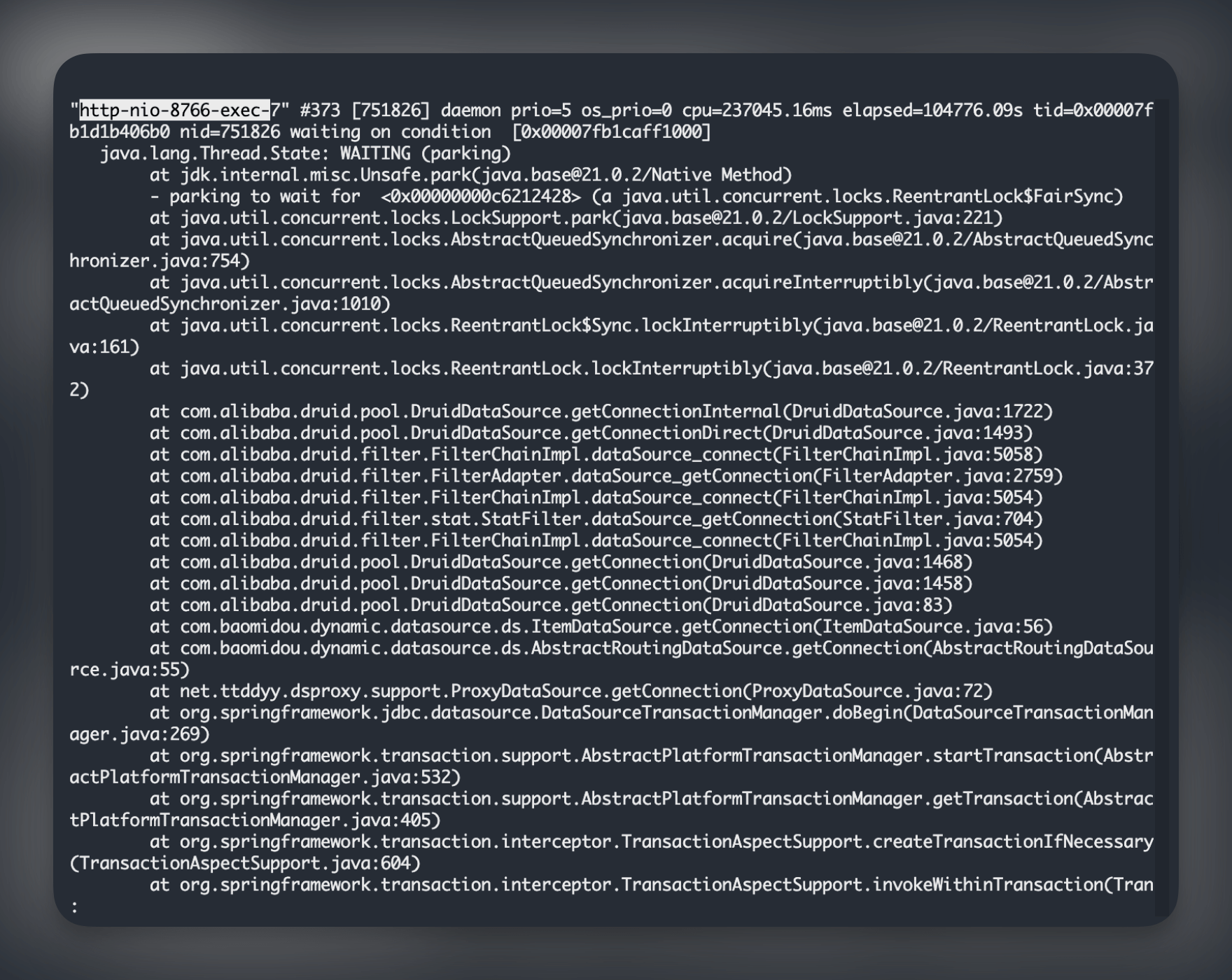
而且几乎所有 WAITING 状态的都来自 Druid 数据库连接池获取不到链接, 争抢锁 🔒 时获取不到, 一直等待其他链接的释放.

我们的在服务配置的 max-active = 20, 说明 20 个链接可能都被占着, 一直没还回去.
难道是高并发? 是不是要直接把 max-active 调大就可以解决? 如果我是初级开发, 我可能就会认为这样就能解决了, 毕竟舔了这堆屎山 💩 已经近 3 年之久, 我的直觉告诉我肯定是哪里有 Bug 导致的
因为还没给 Druid 配置连接泄漏检测, 所以只能通过业务日志排查.因为是一直有线程占数据库连接「不拉屎」, 导致后面的请求「拉不了屎」, 所以我们可以从日志最前面的几个 http 请求线程来看.
发现均来自给设备升级的业务, 这个业务的接口在开发环境一般是了半夜 2 点定时任务触发的, 很少在从客户端请求
有点眉目了
本来想看能不能知道几个线程的存活时间, 通过存活时间来推算日志时间来看业务日志, 转念一想, 都已知具体触发时间, 就搭配线程名和业务关键来过滤日志吧, 就在日志的海洋 🌊 里遨游吧, 骚年
排查了好一会儿, 突然发现有几个 Feign 的调用是报错的, 通过 trace 来看, 看到本应该 2 点开始出发的请求, 在 9 点还有一个报错堆栈:
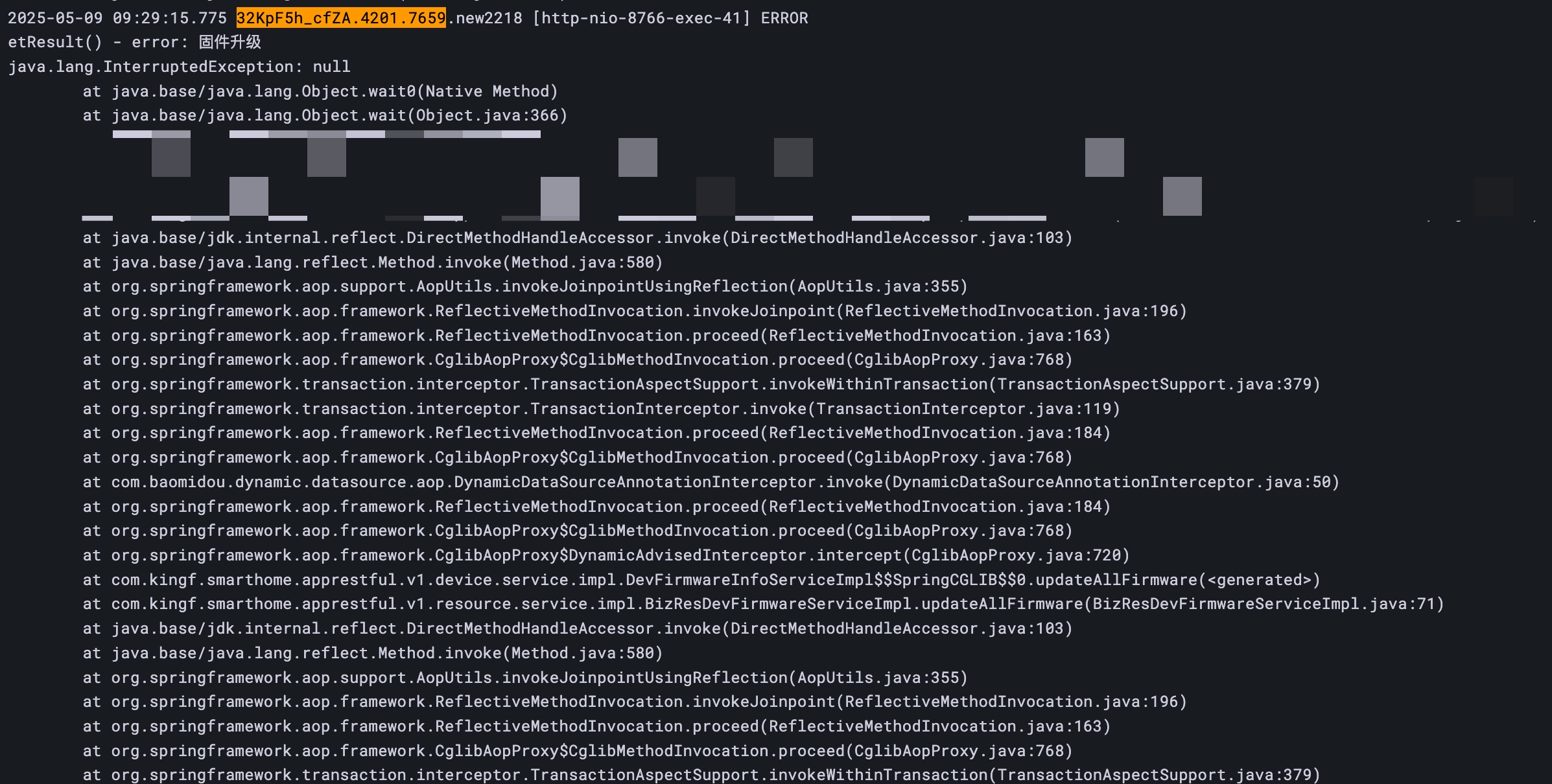
奇怪, 怎么有一个 wait 被中断的报错, 而且在 过了 7 个小时才被中断.
java.lang.InterruptedException: null
at java.base/java.lang.Object.wait0(Native Method)
at java.base/java.lang.Object.wait(Object.java:366)找到对应的代码, 发现是同事在解耦一个业务的时候, 想把一个兜底的定时任务去掉, 写成了一个 while(可能会真) 里加了个 object.wait(时间).
那么我们看下这几个一直 wait 的请求吧.对了, 这里的线程应该是为 TIMED_WAITING 状态, 因为是加了等待时间的, 只是一直在 while 里出不来.
终于捉到虫
再次请出我们的 Linux 剑客帮帮忙吧, 记得把想要找的线程状态改为 TIMED_WAITING
awk '/^"/ {thread=$0} /java.lang.Thread.State: TIMED_WAITING/ {print thread}' thread_dump.log | awk -F'"' '{print $2}'输出内容:
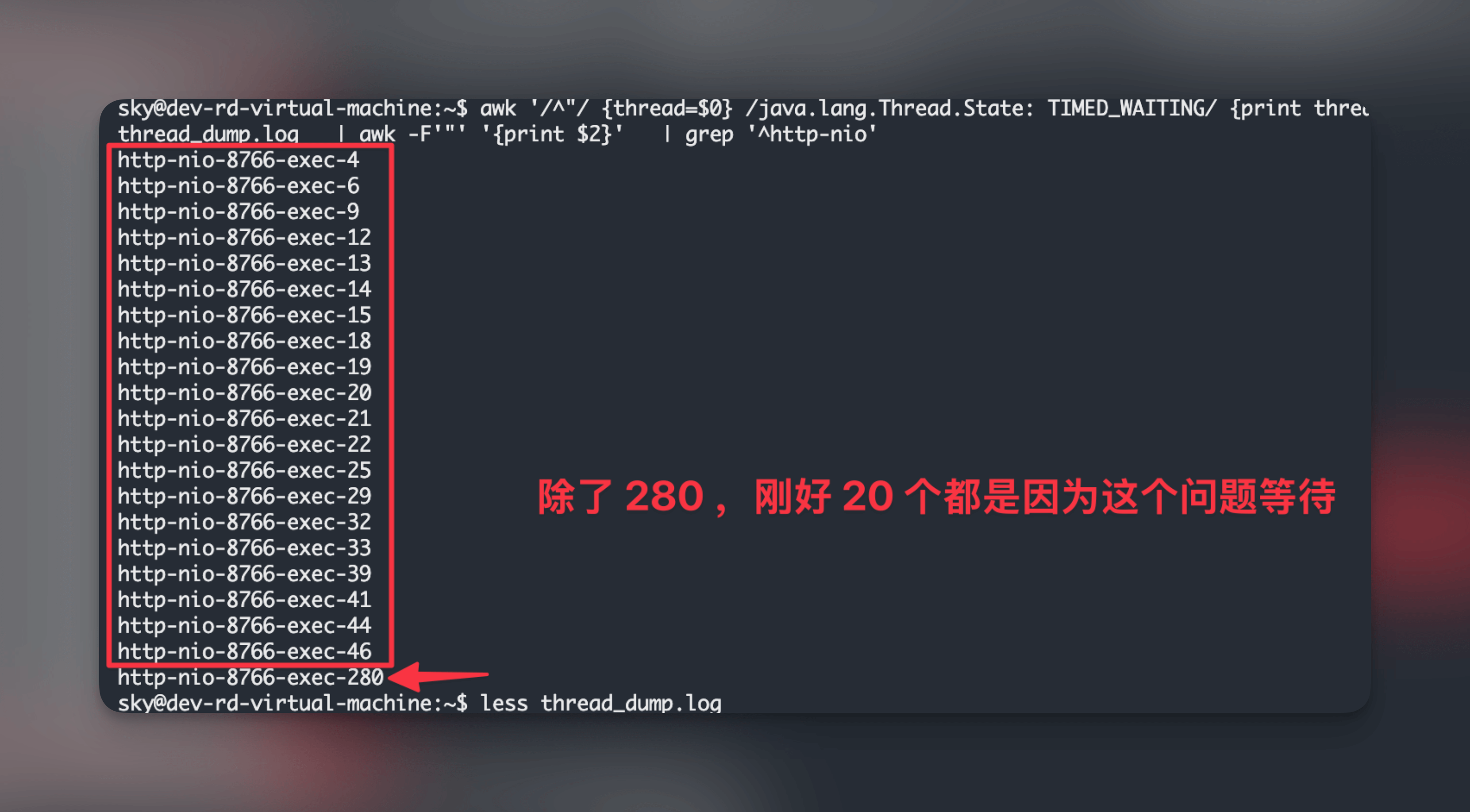
看了除了 http-nio-exec-280 外的日志, 都是卡在出问题的代码上:
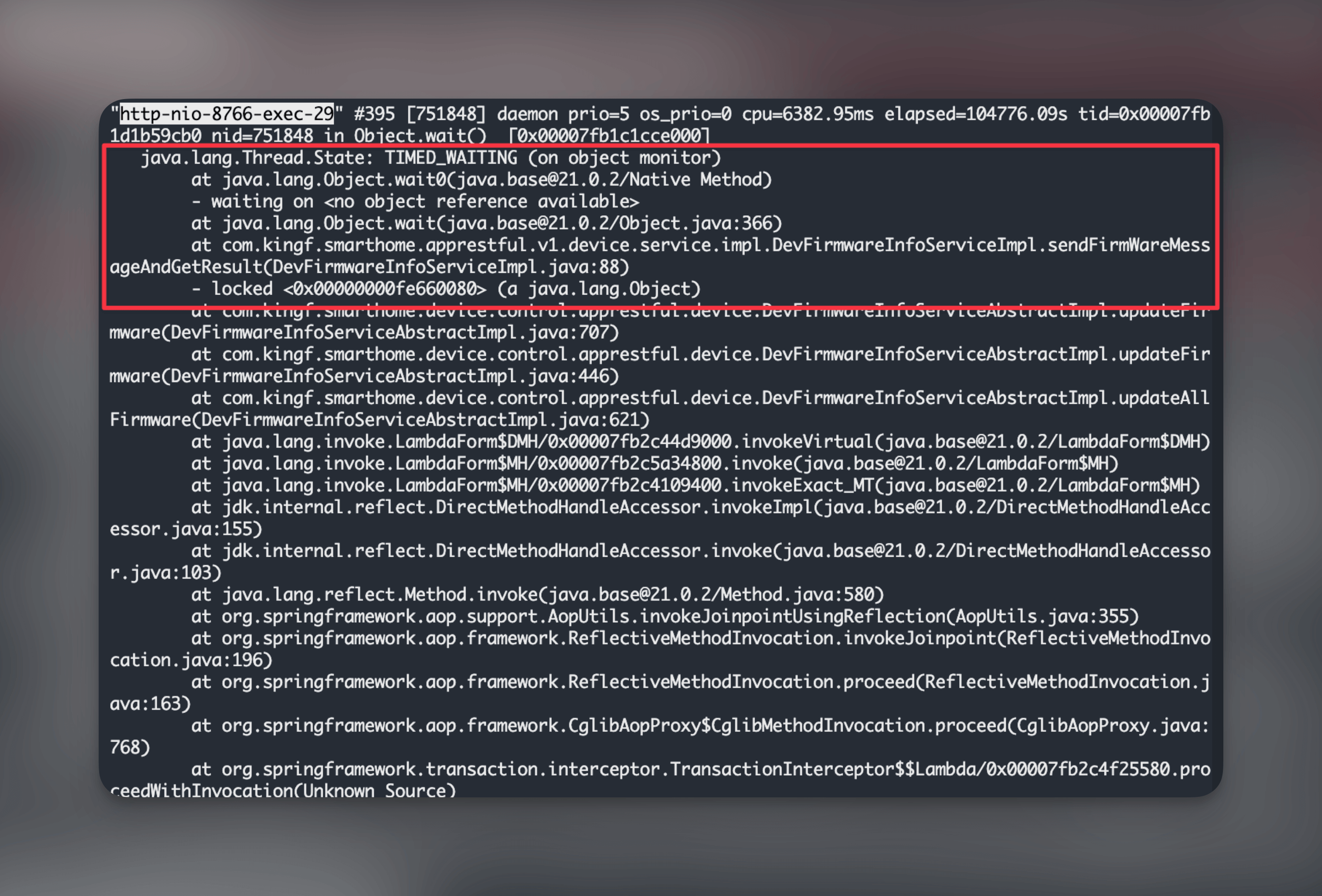
而且刚好数量和配置的 Druid 的 max-active 一致, 这个 Bug 就在这里被排查出来了.
因为有个监控会定时调用「登陆」接口来判断服务是否正常, 所以后面 200+ 个请求积压都是来自「登陆」接口.
学到了啥
和以前排查 bug 不同的是, 这次排查问题读组件源码, 通过报错堆栈搜问题, 以前会在首先会 Google 搜索, 现在首先是发给 ChatGPT.
虽然 AI 输出的内容可能比较全面, 但是还是会误导我们, 比如这次解决问题时候, 他因为不知道我们业务代码, 第一时间是让我修改数据库连接池的最大活跃数, 都是一个治标不治本的做法, 如果想要思考问题透彻点, 还是多问 Why, 多用第一性原理分析 🧐